
🚀TL;DR: VSTAR enables pretrained text-to-video models to generate longer videos with dynamic visual evolution in a single pass, without finetuning needed.
Despite tremendous progress in the field of text-to-video (T2V) synthesis, open-sourced T2V diffusion models struggle to generate longer videos with dynamically varying and evolving content. They tend to synthesize quasi-static videos, ignoring the necessary visual change-over-time implied in the text prompt. At the same time, scaling these models to enable longer, more dynamic video synthesis often remains computationally intractable. To address this challenge, we introduce the concept of Generative Temporal Nursing (GTN), where we aim to alter the generative process on the fly during inference to improve control over the temporal dynamics and enable generation of longer videos. We propose a method for GTN, dubbed VSTAR, which consists of two key ingredients: 1) Video Synopsis Prompting (VSP) - automatic generation of a video synopsis based on the original single prompt leveraging LLMs, which gives accurate textual guidance to different visual states of longer videos, and 2) Temporal Attention Regularization (TAR) - a regularization technique to refine the temporal attention units of the pre-trained T2V diffusion models, which enables control over the video dynamics. We experimentally showcase the superiority of the proposed approach in generating longer, visually appealing videos over existing open-sourced T2V models. We additionally analyze the temporal attention maps realized with and without VSTAR, demonstrating the importance of applying our method to mitigate neglect of the desired visual change over time. Further, based on the analysis of various T2V mdoels, we provide insights on how to improve the training of the next generation of T2V models.
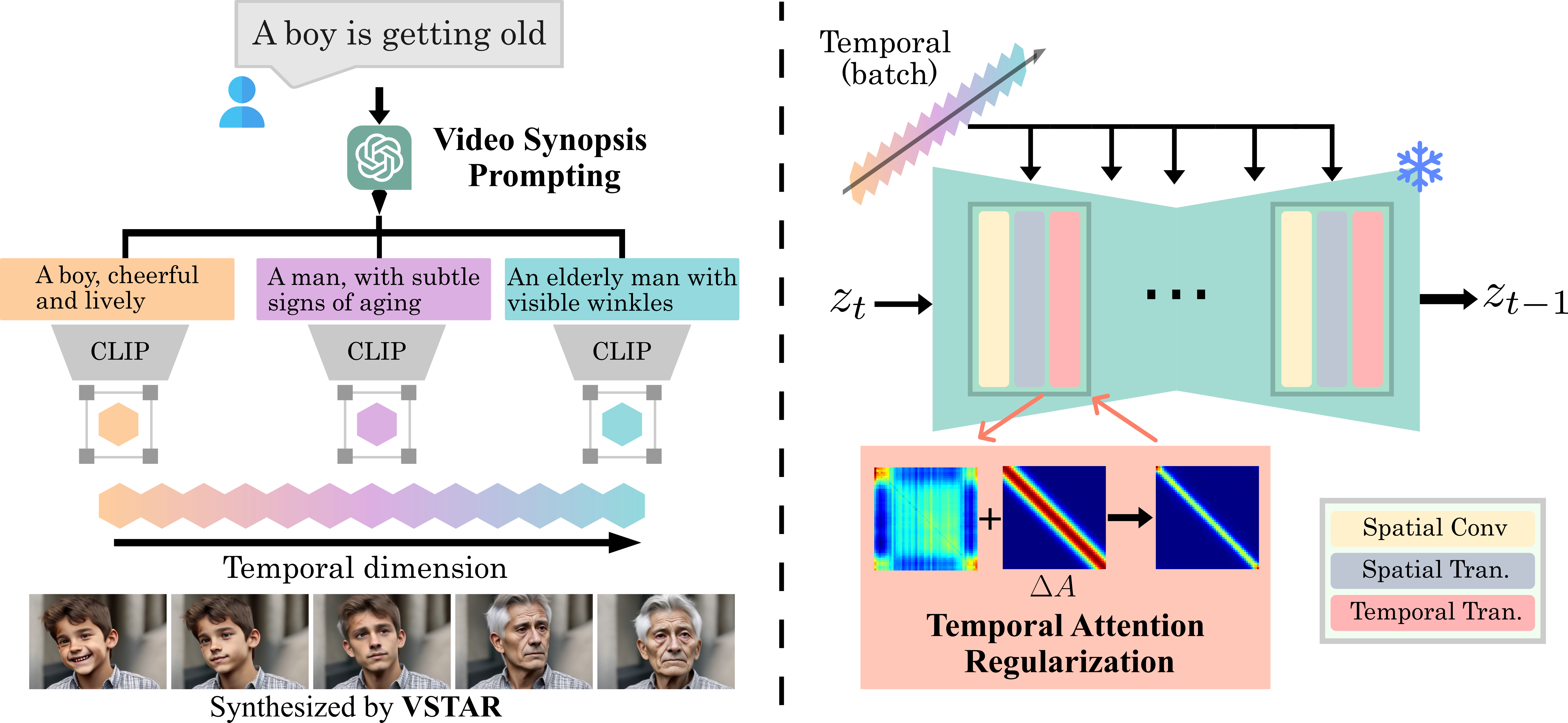
Our VSTAR consists of two strategies: Video Synopsis Prompting (left) and Temporal Attention Regularization (right).

Instead of using the same single prompt for all frames, Video Synopsis Prompting leverages the ability of large language models (LLMs), to decompose the single input prompt describing a dynamic transition into several stages of visual development. VSP can thus provide the T2V model more accurate guidance on individual visual states, encouraging diversity from the spatial perspective. It is sufficient to generate text descriptions for the main event changes in a video rather than for each frame. Text embeddings of these descriptions, which are then interpolated to guide each frame's synthesis via cross attention.

For both 16 and 48 frame real videos, the attention matrix manifests as a band-matrix-like structure. Intuitively, closer frames should have a higher correlation with each other to maintain temporal coherency. Compared to real videos, attention matrix of the synthetic ones is less structured, especially for 48 frames. That explains why the model generalizes even worse to longer videos. High correlation is spread across a wide range of frames, resulting in a harmonized sequence with similar appearances.

Further, we conducted a per-resolution ablation. We replace the attention map at individual resolution, i.e., 64, 32, 16, 8 and 64 & 32 while keeping the other resolution untouched. We experiment with two extreme cases: using the Identity matrix and the all-ones matrix, making the results more dynamic (1st row) or more static (2nd row). We can conclude that manipulating temporal attention allows us to alter the video dynamics. In particular, adjustments at higher resolutions, e.g. 64 & 32, are more effective.
To approximate such a structure, we design a symmetric Toeplitz matrix as the regularization matrix ΔA, with its values along the off-diagonal direction following the Gaussian distribution. The standard deviation σ can control the regularization strength. i.e. larger σ leading to less visual variations along the temporal dimension. This regularization matrix is then added to the original attention matrix.
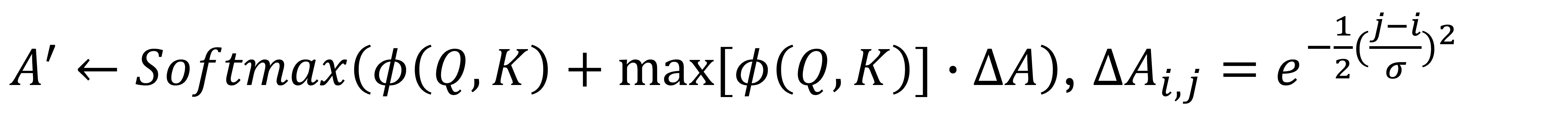


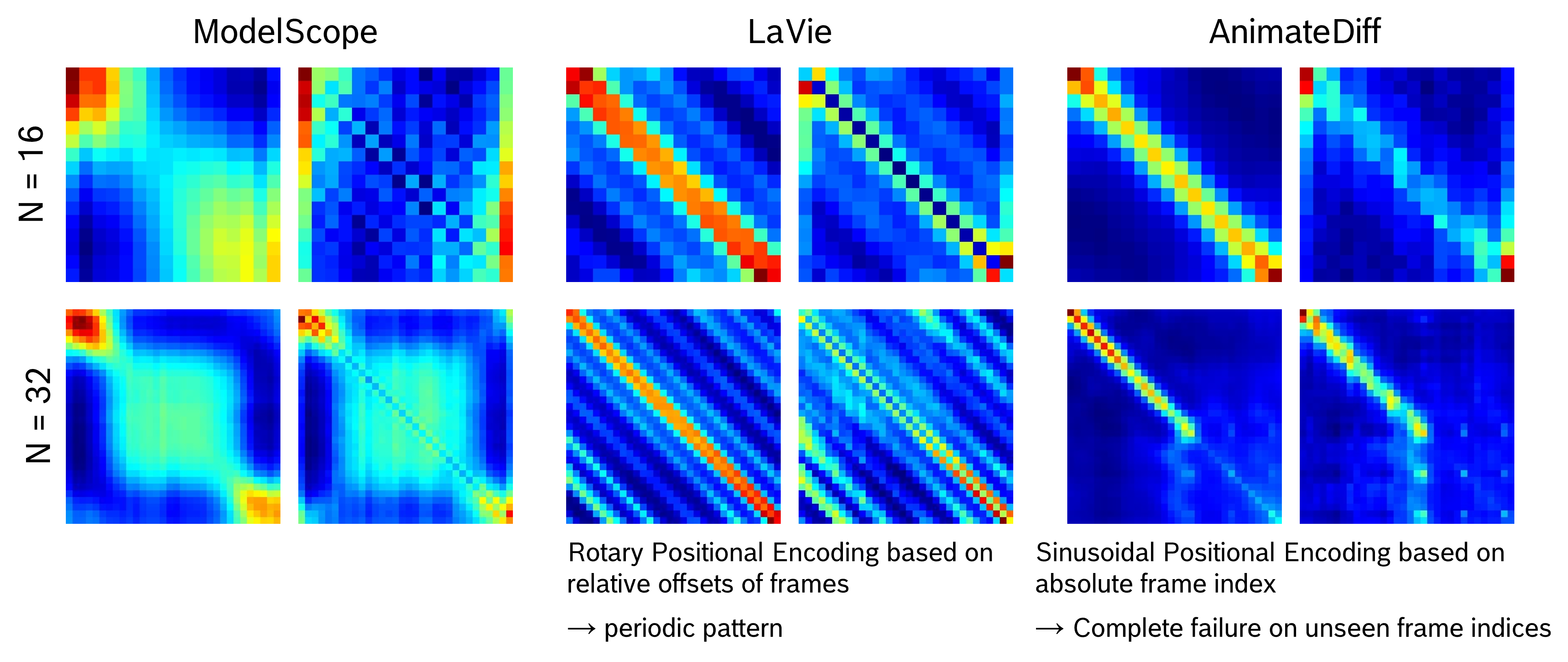
When generating 32 frames in one pass, which is double the length of the default option. Our VSTAR can generate long videos with desired dynamics, while the others struggle to synthesize faithful results. From the temporal attention visualization of other T2V models, we identify the poor generalization of longer video generation comes from the positional encoding. This offers valuable insights into improving the training of the next generation of T2V models, such as employ a better combination of data format and positional encodings or incorporating regularization loss on the temporal attention maps.





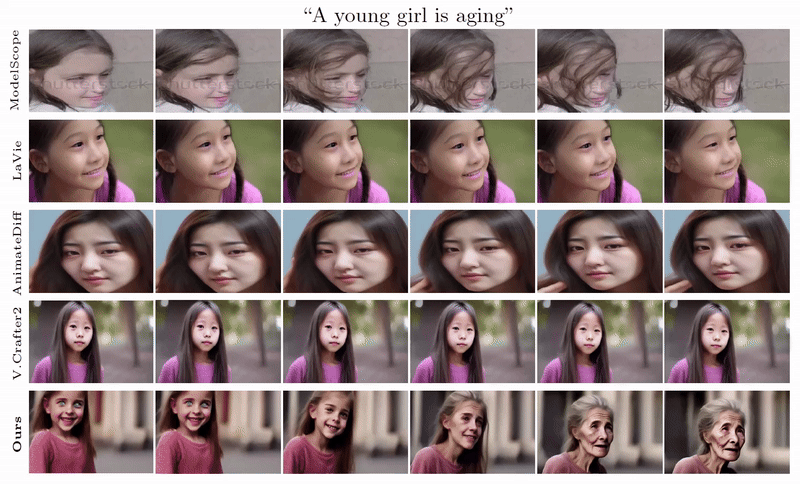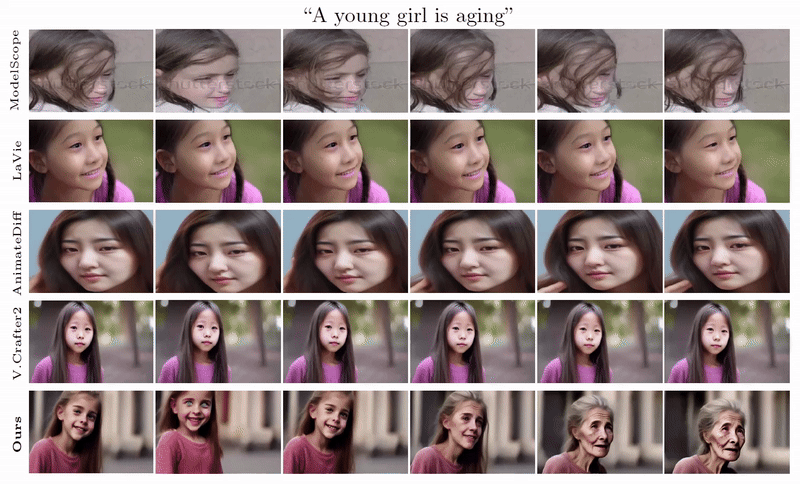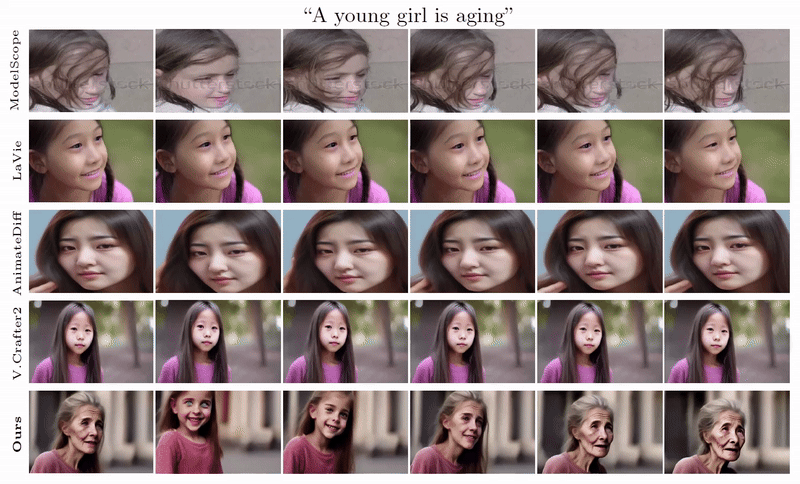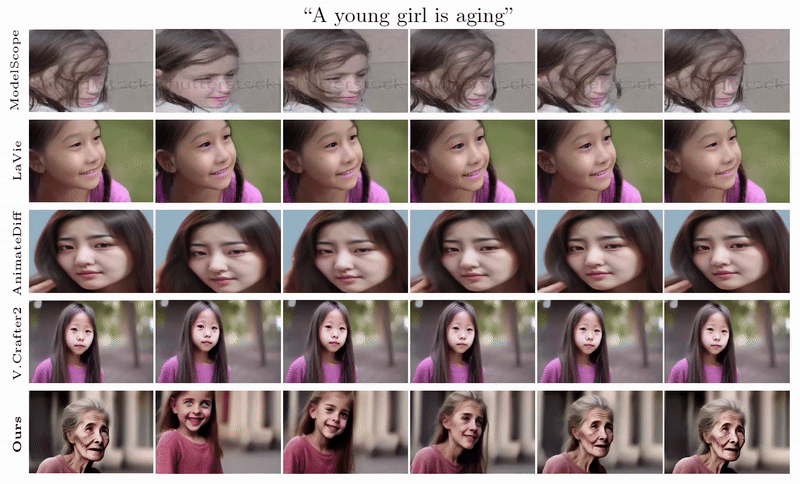
@article{li2024vstar,
title = {VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis},
author = {Yumeng Li and William Beluch and Margret Keuper and Dan Zhang and Anna Khoreva},
journal = {arXiv preprint arXiv:2403.13501},
year = {2024},
}